SPEAK YOUR MIND! Towards Imagined Speech Recognition With Hierarchical Deep Learning
Pramit Saha, Praneeth Srungarapu, Sidney Fels
Abstract
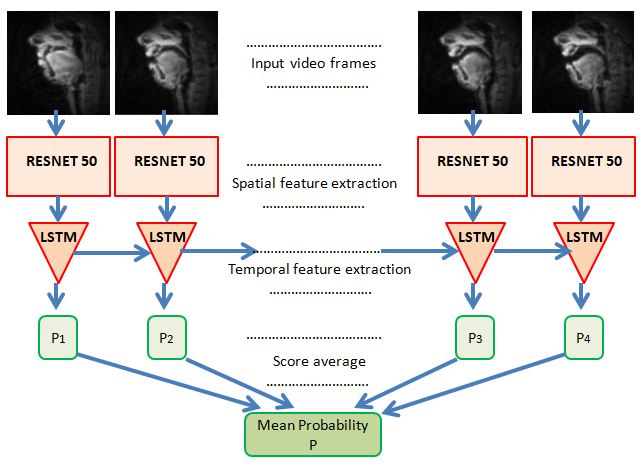
Vocal tract configurations play a vital role in generating distinguishable speech sounds, by modulating the airflow and creating different resonant cavities in speech production. They contain abundant information that can be utilized to better understand the underlying speech production mechanism. As a step towards automatic mapping of vocal tract shape geometry to acoustics, this paper employs effective video action recognition techniques, like Long-term Recurrent Convolutional Networks (LRCN) models, to identify different vowel-consonantvowel (VCV) sequences from dynamic shaping of the vocal tract. Such a model typically combines a CNN based deep hierarchical visual feature extractor with Recurrent Networks, that ideally makes the network spatio-temporally deep enough to learn the sequential dynamics of a short video clip for video classification tasks. We use a database consisting of 2D realtime MRI of vocal tract shaping during VCV utterances by 17 speakers. The comparative performances of this class of algorithms under various parameter settings and for various classification tasks are discussed. Interestingly, the results show a marked difference in the model performance in the context of speech classification with respect to generic sequence or video classification tasks.
Dive into our research!
<a href=https://arxiv.org/pdf/1807.11089”>📄 Paper</a>