Learning Joint Articulatory-Acoustic Representations with Normalizing Flows
Pramit Saha and Sidney Fels
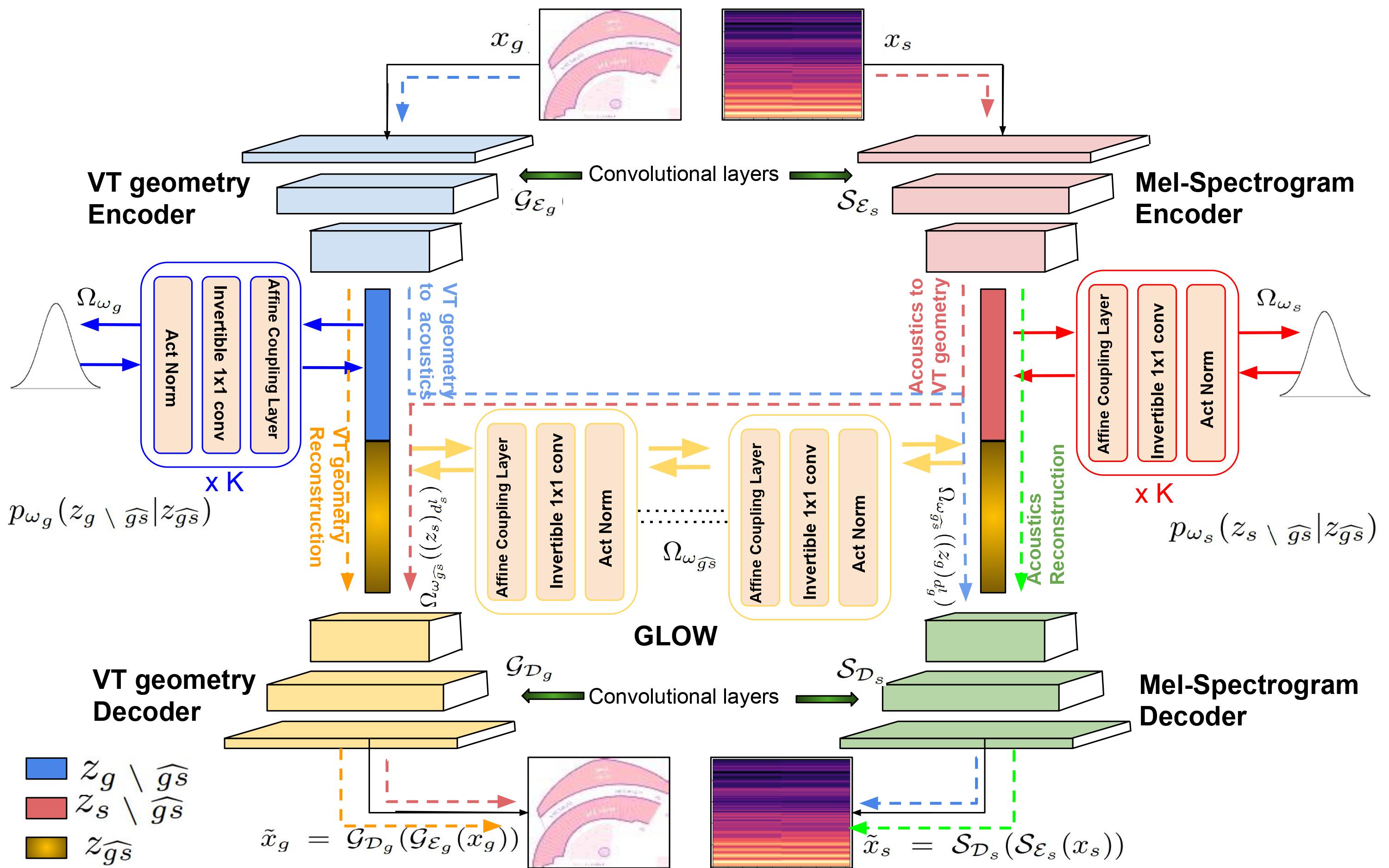
Abstract The articulatory geometric configurations of the vocal tract and the acoustic properties of the resultant speech sound are considered to have a strong causal relationship. This paper aims at finding a joint latent representation between the articulatory and acoustic domain for vowel sounds via invertible neural network models, while simultaneously preserving the respective domain-specific features. Our model utilizes a convolutional autoencoder architecture and normalizing flow-based models to allow both forward and inverse mappings in a semi-supervised manner, between the mid-sagittal vocal tract geometry of a two degrees-of-freedom articulatory synthesizer with 1D acoustic wave model and the Mel-spectrogram representation of the synthesized speech sounds. Our approach achieves satisfactory performance in achieving both articulatory-to-acoustic as well as acoustic-to-articulatory mapping, thereby demonstrating our success in achieving a joint encoding of both the domains.
Dive into our research!