Ultra2Speech - A Deep Learning Framework for Formant Frequency Estimation and Tracking from Ultrasound Tongue Images
Pramit Saha, Yadong Liu, Bryan Gick, and Sidney Fels
Abstract
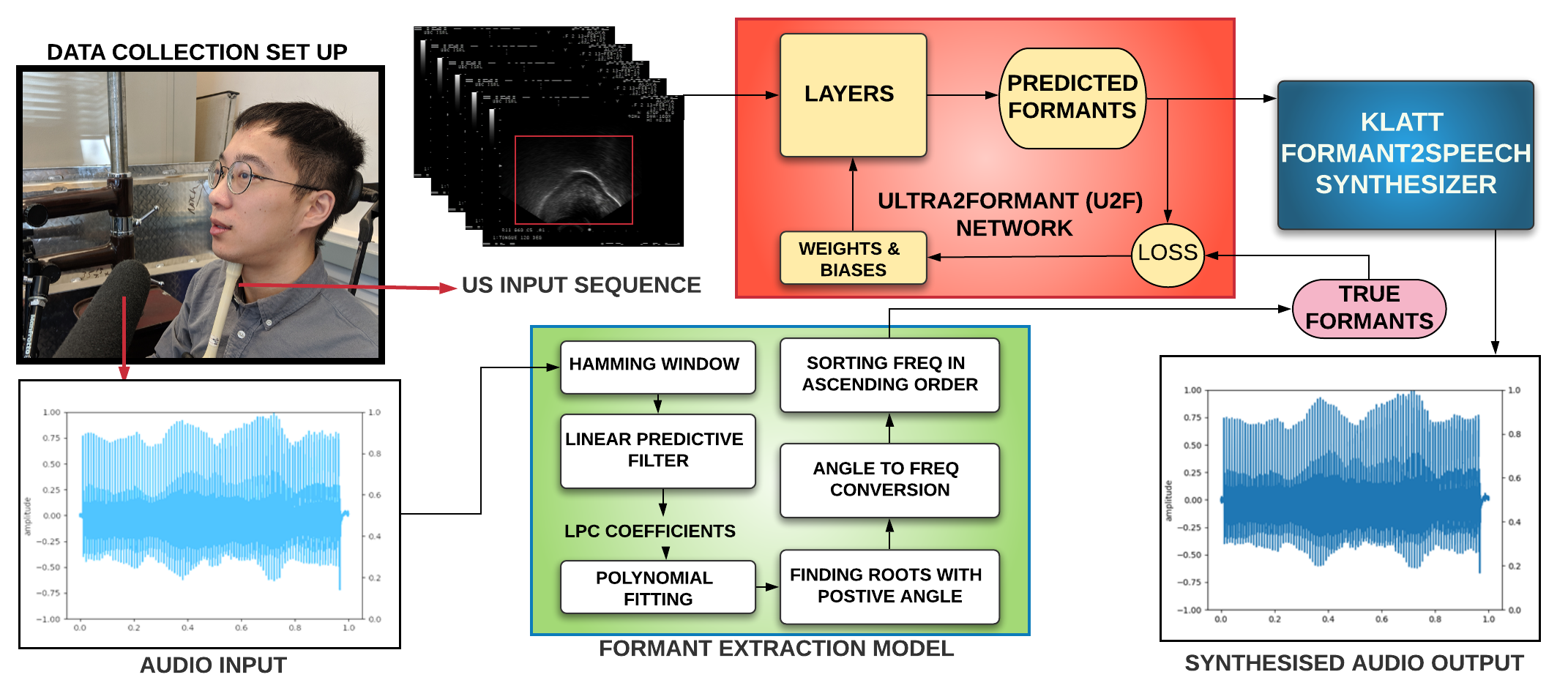
Thousands of individuals need surgical removal of their larynx due to critical diseases every year and therefore, require an alternative form of communication to articulate speech sounds after the loss of their voice box. This work addresses the articulatory-to-acoustic mapping problem based on ultrasound (US) tongue images for the development of a silent-speech interface (SSI) that can provide them with an assistance in their daily interactions. Our approach targets automatically extracting tongue movement information by selecting an optimal feature set from US images and mapping these features to the acoustic space. We use a novel deep learning architecture to map US tongue images from the US probe placed beneath a subject’s chin to formants that we call, Ultrasound2Formant (U2F) Net. It uses hybrid spatio-temporal 3D convolutions followed by feature shuffling, for the estimation and tracking of vowel formants from US images. The formant values are then utilized to synthesize continuous time-varying vowel trajectories, via Klatt Synthesizer. Our best model achieves R-squared (R2 ) measure of 99.96% for the regression task. Our network lays the foundation for an SSI as it successfully tracks the tongue contour automatically as an internal representation without any explicit annotation
Dive into our research!